Linkerdでサービスメッシュを構築してKubernetesクラスタのメトリクスを見る

動機
ひとり趣味で作っている機械学習サービスをマイクロサービス化してGoogle Kubernetes Engine(GKE)で構築しています。
しかし、外部からアクセスした時にレスポンスタイムが突発的にスパイクすることがわかりました。
Grafanaで可視化すると以下のようです。
ネットワーク実験したのですが、どうやら外部クライアントからアクセスしたときに起きるようです。 内部のPod -> Pod間の通信では問題がありませんでした。
今回はLinkerdでサービスメッシュを構築して、実際に何が起きているのかを調査しようと思います。
なお、執筆時には結果が分かっていなかったですが、Linkerdとこれとは別にPrometheus + Grafanaで原因がわかりました。
内容
Linkerdについて
公式ページ
概要
公式ページでは以下のように書いてあります。
Linkerd gives you instant Grafana dashboards and CLI debugging tools for any Kubernetes service — with no cluster-wide installation
日本語にすると
Linkerdはクラスタに及ぶインストールなしで任意のKubernetesサービスインスタントなGrafanaダッシュボードとCLIでバッキングツールを提供する
です。Sidecarを提供し、Service Meshを構築するものです。
特徴
ランタイムをデバックしやすく、可観測しやすく、信頼性が高く、セキュアにできます。また、以下のような特徴があります。
特にアプリケーションのコードは一切変えなくていいです。
- 迅速なランタイム問題の診断
- 実行可能なサービスメトリクスの収集
- ゼロ設定、すぐインストールできる
- インクリメンタルに構築できるデザイン
- 軽量である
- Rustで書かれていてクラウドネイティブである
Architecture
三つの柱があります。
- WebAPI: Web DashboardやCLIツールのリクエストを受け付ける
- Data Plane
- Control Plane
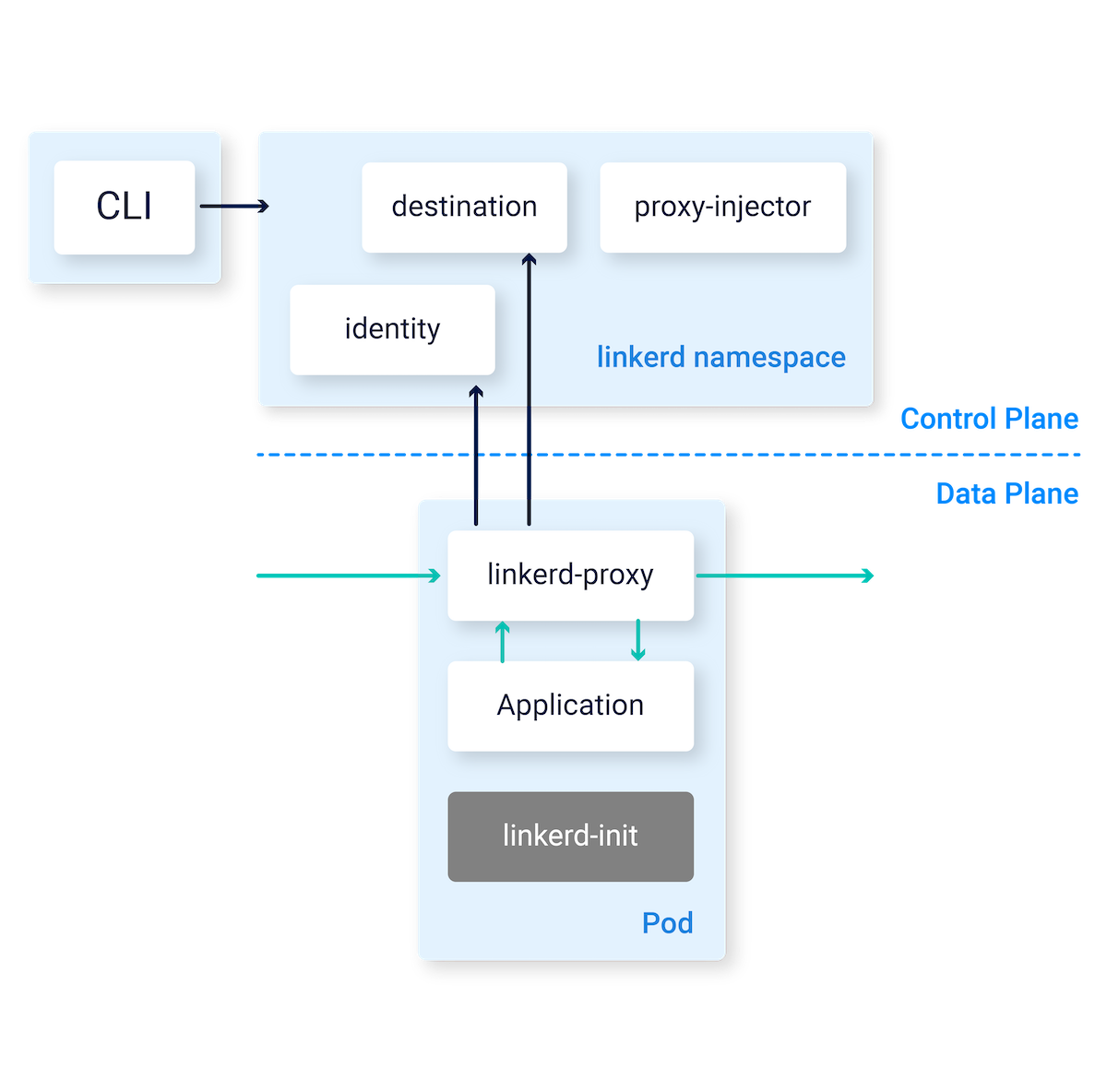
デフォルトではlinkerdnamespaceで構築される。
Control Plane
まず、最初にインストールするようになる。
四つの構成要素がある。
| 構成要素 | 内容 |
|---|---|
| controller | public-api, proxy-api, destination, tapコンテナを含み、linkerdの機能を提供する |
| web | dashboardを提供する |
| Prometheus | Linkerdから出力されるメトリクスを収集して保存する |
| Grafana | いろんなダッシュボードを提供する。 |
Prometheus
Linkerdメトリクスを収集し、保存している。
Proxyのメトリクスも保存している。

Grafana
全体のメトリクスからPod一つ一つの情報も提供する。

Data Plane
主にDataを提供する領域だと思えばいいと思います。
Proxy
軽量なSidecarプロキシであり、すべてのPodに付随しないといけない。CLIコマンドで追加することができる。
Linkerdインストール
1. クラスタ情報を取得できているかチェック
credentialなど設定など色々あると思うので、チェックすることができます。
また、以下のようにいろんな項目をチェックすることができます。
$ linkerd check --pre kubernetes-api: can initialize the client..................................[ok] kubernetes-api: can query the Kubernetes API...............................[ok] kubernetes-api: is running the minimum Kubernetes API version..............[ok] kubernetes-setup: control plane namespace does not already exist...........[ok] kubernetes-setup: can create Namespaces....................................[ok] kubernetes-setup: can create ClusterRoles..................................[ok] kubernetes-setup: can create ClusterRoleBindings...........................[ok] kubernetes-setup: can create ServiceAccounts...............................[ok] kubernetes-setup: can create Services......................................[ok] kubernetes-setup: can create Deployments...................................[ok] kubernetes-setup: can create ConfigMaps....................................[ok] linkerd-version: can determine the latest version..........................[ok] linkerd-version: cli is up-to-date.........................................[ok] Status check results are [ok]
okが出たので次に進みましょう。
2. LinkerdのControl Planeをインストール
以下のコマンドでインストールします。namespaceはlinkerdです。
最初にnamespaceがないことを確認しましょう。
先ほどのcheckコマンドでも以下の項目がありましたが、確認してみます。
kubernetes-setup: control plane namespace does not already exist...........[ok]
ここではnamespaceを出力してみます。
$ kubens

ここでmonitorに使っていたのは、以下のようにコンピューターリソースなどをチェックするためにPrometheus + Grafanaを使っていたためです。
なので、なくても気にしないでください。

まだLinkerdがインストールされていないことが確認できたので、以下のコマンドでインストールします。
linkerd install | kubectl apply -f -
1分か2分ぐらいかかりますが、終了後は以下のコマンドでインストールが成功しているかチェックできます。
最初はcontrollerがクラッシュしていたので心配でしたが、無事いけました。
また、エラーが出てインストールできない場合もあります。
そのときはCluseterRoleを作ることで解決することができます。
kubectl create clusterrolebinding cluster-admin-binding \ --clusterrole cluster-admin \ --user $(gcloud config get-value account)
Podを取得します。
$ kubectl get pods --namespace linkerd controller-d6f584b7d-w2zd2 5/5 Running 18 12m grafana-d57f845dd-s2b5s 2/2 Running 0 12m prometheus-6b979dc67d-dldbf 2/2 Running 0 12m web-559f7d6745-989ll 2/2 Running 0 1m
無事ありますね。
$ linkerd check kubernetes-api: can initialize the client..................................[ok] kubernetes-api: can query the Kubernetes API...............................[ok] kubernetes-api: is running the minimum Kubernetes API version..............[ok] linkerd-api: control plane namespace exists................................[ok] linkerd-api: control plane pods are ready..................................[ok] linkerd-api: can initialize the client.....................................[ok] linkerd-api: can query the control plane API...............................[ok] linkerd-api[kubernetes]: control plane can talk to Kubernetes..............[ok] linkerd-api[prometheus]: control plane can talk to Prometheus..............[ok] linkerd-version: can determine the latest version..........................[ok] linkerd-version: cli is up-to-date.........................................[ok] linkerd-version: control plane is up-to-date...............................[ok] Status check results are [ok]
大丈夫です。
3. ダッシュボードの確認
以下のコマンドでダッシュボードを確認します。
linkerd dashboard
以下のように自動的に開かれました。デフォルトのブラウザで開かれます。

Control PlaneはすべてProxyが入っているので見ることができます。
しかし、Data Plane(アプリケーションのPod)の方はProxyが入っていないので、なにも取得していない状態なので何も見ることができません。
たとえば以下のようなdefault namespaceは以下のようなリソースがあります。
$ kubectl get pods grafana-1-6f5db8cf47-pcjvj 1/1 Running 0 12h crob-job-duration 0/1 Completed 0 12h ...
しかしData PlaneにProxyをデプロイできていないので、何もメトリクスは取得できていないです。赤枠はセキュリティ的都合からお見せできないものです。すみません。

対応関係とは
- Deployment: Serviceのこと
- Pod: Podそのまま
です。
4. 自前リソースにSidecarのInjectする
以下のコマンドでリソースファイルにInjectします。
linkerd inject deployment.yml \ | kubectl apply -f -
ここでhelmを使っている人はGo templateの結果を出力して渡す必要があります。この操作はTillerを必要としないのでhelm chartがあれば良いです。
Kubernetesのマニフェストファイルを出力するには
helm template [CHART名] -x [単一テンプレート]
ここの単一テンプレートはChart.yamlがあるディレクトリからの相対パスを指定するようになります。
たとえば以下のようになります。
helm template mychart -x templates/deployment.yaml
これをlinkerdに渡すには
helm template mychart -x templates/deployment.yaml | linkerd inject deployment.yml \ | kubectl apply -f -
ようにすれば大丈夫です。
実際にやってみます。Proxyを挟みたいのは以下の色のついたPodです。

これを先ほどのものに入れ替えます。
間違ってレプリカ数を変えてしまいました。リソースの観点からNode数も変更しました。

ここで新しくメトリクスを取れていることがわかります。

コンテナ数もRust製の軽量Proxy分増えています。
同様にtest-1 DeploymentもProxyも導入します。

導入できました。これによってネットワークテストができるようになりました。
5. メトリクスの項目
以下のような項目になっていて、これはDeploymentとPodは一緒です。

以下のような項目に分かれています。
| 項目 | 内容 |
|---|---|
| MESHED | Proxyが設定されている数 / Podの数。ProxyはPod数にも設定されている数にも入ります。 |
| SR | Success Rate。リクエストの成功率。 |
| Request Rate | ---- |
| P50 Latency | 直近10秒間のリクエストの遅い50%の平均値 |
| P95 Latency | 直近10秒間のリクエストの遅い95%の平均値 |
| P99 Latency | 直近10秒間のリクエストの遅い99%の平均値 |
| TLS | Percentage of TLS Traffic。 |
PXXが意味するところは
PXXとは最近 10 秒間で最も遅かったリクエストの XXパーセントの平均レイテンシーです。たとえば、P99 は、直近の 10 秒間で最も遅かった 1% のリクエストのレイテンシーを表します。
図を書いてみました。

つまりXXが大きければ大きいほど遅いものに注目できる反面、局所的になるかもしれないことを示します。
すでに分かっている人も多いかもしれませんが、極端に遅いものがあり速度に差があるようなケースはP99が大きく、P99に比べてP50が小さいです。逆に、なだらかに差があるときはP50とP99の差は少ないです。
このような情報から、トラフィックの安定度を知ることができます。
詳しくは以下の文献を見るといいかもです。
ここで注意して欲しいのは以下のコマンドのREADYに出る数はPodに含まれるコンテナ数です。なのでcontrollerのPodは一つです。
$ kubectl get pods NAME READY STATUS RESTARTS AGE controller-d6f584b7d-w2zd2 5/5 Running 18 32m grafana-d57f845dd-s2b5s 2/2 Running 0 32m prometheus-6b979dc67d-dldbf 2/2 Running 0 32m web-559f7d6745-989ll 2/2 Running 0 21m
6. 特定のGrafanaダッシュボードを覗く
Top Line
全体の俯瞰的なダッシュボードです。

Service
以下のようなサービスが使えます。

LBに関わるようなメトリクスを取得することができます。
項目をクリックすると以下のようになります。

そこに書いてあるPXXは、そのServiceに入って、レスポンスを返すまでの時間で、それをInbound Trafficと呼びます。
Deployment
Deployはプレフィクスがdeploy/が付いています。

特にPodが複数あるときに活躍してきそうな感じはあります。
またLinkerdの管理画面では以下のようになっています。

Pod
Podはプレフィクスがpo/が付いています。

以下のようにProxyがあるため、InboundとOutboundのトラフィックを取得することができます。
ここで
Inbound: 外部からそのサービスにトラフィックが流れ、レスポンスを返すまで。その時の外部通信などを全て含む。通信クライアントがServiceの場合はそのサービスの値が出る。たとえばtest-2のInboundはtest-1である。Outbound: そのサービスが使っている他のService。たとえばここならtest-1のOutboundはtest-2である。
Inbound

Outbound

7. ストリームをみる
stat
statはかなりハイレベルなレイヤーの監視をすることができる。
以下のようなコマンドを走らせることで見ることができます。
ストリームではなく、バッジ的に値を算出するので一時的に状態が知りたい時は使うべきだと思います。
linkerd stat deploy NAME MESHED SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99 TLS test-1-65dbdfd5d4-hr8bp 1/1 100.00% 3.2rps 6ms 10ms 17ms 0%
もっとも重要な
- Success rates
- Request rates
- Latency distribution percentiles
を見ることができます。
top
statよりも具体的にパスごとに何が起きているのかを確認することができます。f
具体的な通信状態がわかるのが良いと思います。
以下のようにパスごとのメトリクスを知ることができるのです。
linkerd top deploy (press q to quit) Source Destination Path Count Best Worst Last Success Rate test-1-65dbdfd5d4-hr8bp ml-857d5d5786-q4pj9 /v1/test 37 3ms 8ms 5ms 100.00% 10.20.3.1 ml-857d5d5786-q4pj9 /healthy 2 3ms 4ms 4ms 100.00%
WebUIでは以下の通りです。

tap
以下のコマンドで具体的なServiceごとで見ることができます。 ストリームで見られることが特徴ではないでしょうか。
絶え間なく、各々のストリームについて知ることができます。
linkerd tap deploy/hoge req id=0:10115 proxy=out src=10.20.5.3:55696 dst=10.20.3.18:5000 tls=no_identity :method=POST :authority=ml:5000 :path=/v1/test-1 rsp id=0:10115 proxy=out src=10.20.5.3:55696 dst=10.20.3.18:5000 tls=no_identity :status=200 latency=4180µs end id=0:10115 proxy=out src=10.20.5.3:55696 dst=10.20.3.18:5000 tls=no_identity duration=130µs response-length=15B rsp id=0:10114 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled :status=204 latency=6891µs end id=0:10114 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled duration=0µs response-length=0B req id=0:10116 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled :method=POST :authority=35.221.110.170:5050 :path=/v1/test-2 req id=0:10117 proxy=out src=10.20.5.3:55700 dst=10.20.3.18:5000 tls=no_identity :method=POST :authority=ml:5000 :path=/v1/test-1 rsp id=0:10117 proxy=out src=10.20.5.3:55700 dst=10.20.3.18:5000 tls=no_identity :status=200 latency=4474µs end id=0:10117 proxy=out src=10.20.5.3:55700 dst=10.20.3.18:5000 tls=no_identity duration=152µs response-length=15B rsp id=0:10116 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled :status=204 latency=7470µs end id=0:10116 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled duration=0µs response-length=0B req id=0:10118 proxy=in src=10.146.0.5:63684 dst=10.20.5.3:5050 tls=disabled :method=POST :authority=35.221.110.170:5050 :path=/v1/test-2 req id=0:10119 proxy=out src=10.20.5.3:55702 dst=10.20.3.18:5000 tls=no_identity :method=POST :authority=ml:5000 :path=/v1/test-1 rsp id=0:10119 proxy=out src=10.20.5.3:55702 dst=10.20.3.18:5000 tls=no_identity :status=200 latency=4604µs end id=0:10119 proxy=out src=10.20.5.3:55702 dst=10.20.3.18:5000 tls=no_identity duration=143µs response-length=15B ...
WebUIでは以下の通りです。

特にストリームの詳細まで見ることができるので、問題が深いときには見るべき点かなと思いました。

実験
知りたいこと
今回はなぜレスポンスタイムにスパイクが起こるのかを検証していきます。
監視画面
以下のように二つのServiceが見られるようにします。

今回の実験
毎秒3回のリクエストを一つあたり1000回のリクエストを送ります。
内部JobPod -> Pod -> Podの結果
レスポンスタイム

OutboundとInbound

Clusterリソース監視

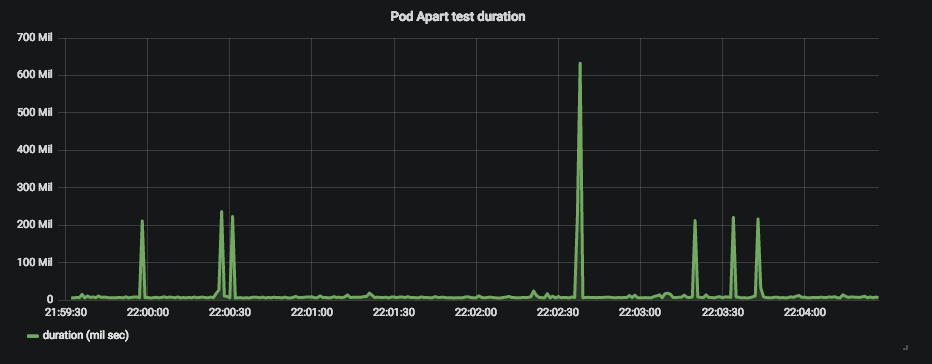
外部クライアントから
レスポンスタイム

OutboundとInbound

Clusterリソース監視

考察
実際に100ms以上のレスポンスを返せていない時は2000rqsであり、現在のテストは3rqsである。
特にスパイクする原因は
- リソースが落ち着いている時は起きない
と考える。負荷試験の必要性があり。
付録
linkerdコマンド
以下のコマンドがあります。
| コマンド | 内容 |
|---|---|
| check | Control Panelのインストールをチェックし、問題を指摘する |
| completion | シェル補完機能を提供する |
| dashboard | ウェブブラウザでdashboardを開く |
| get | 一つ以上のメッシュリソースを取得する |
| help | コマンドのヘルプを開く |
| inject | Kubernetes ConfigにProxyを挿入する |
| install | LinkerdのKubernetesリソースを出力する |
| stat | トラフィック統計値を出力する |
| tap | トラフィックストリームを見る |
| top | ライブトラフィックの集約した情報を表示する |
| version | クライアントとサーバーのバージョンを表示する |